For most podcasts, the voice is the star of the show, so you want the best vocal sound possible. Even with basic audio editing software for Windows or Mac, there are many ways you can improve vocal quality—as these seven tips will show.
1. Get Rid of P-Pops (the Fast Option)
It's always best to get rid of p-pops at the source—by using proper mic technique, windscreens if needed, and a microphone's low-cut filter (if present; see Fig.1).

But if the pops end up getting recorded, then processing the entire vocal track with a very steep low-cut filter (aka high-pass filter) will reduce the pops. Ideally, you want a 48 dB/octave filter slope, maximum cut, and a cutoff frequency (depending on the voice) around 100 to 200 Hz. If that doesn't do the job, you can create a steeper cutoff by putting multiple stages in series (Fig. 2).
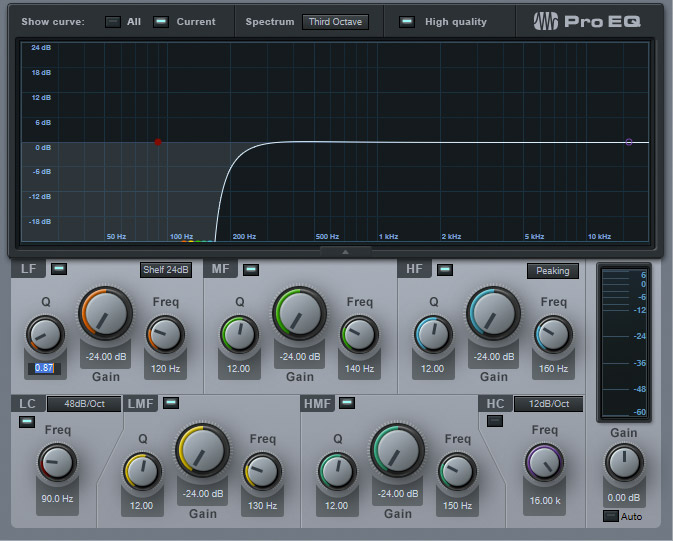
2. Get Rid of P-Pops (the High Fidelity Option)
Taking out the lows from an entire track may get rid of some of the low-frequency vocal "warmth" as well. If there aren't too many pops, you can isolate each one, and add a fade-in over it. Split the vocal clip just before the p-pop, then add the fade-in. Ideally, you want to use an exponential (curved) fade, as shown in Fig. 3, instead of a linear one.
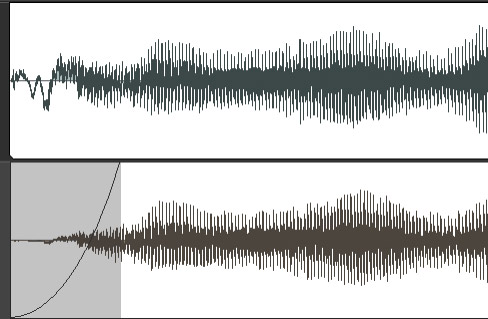
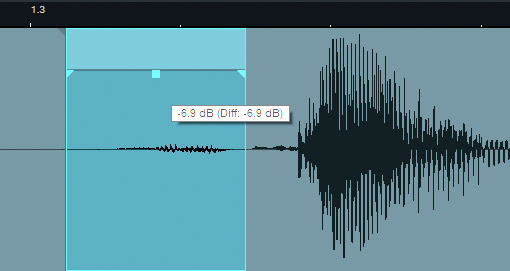
3. More Uniform Levels with Phrase-by-Phrase Normalizing
Sometimes voices trail off, the position in relation to the mic changes, or other issues happen that cause volume variations. For many people, the go-to is using a compressor or limiter to reduce the volume peaks, and raise the lower sections—but this can produce a "squeezed," artificial sound, unless done really carefully. Instead, isolate the lower-level sections, and normalize them to the same level as the louder sections (Fig. 4).
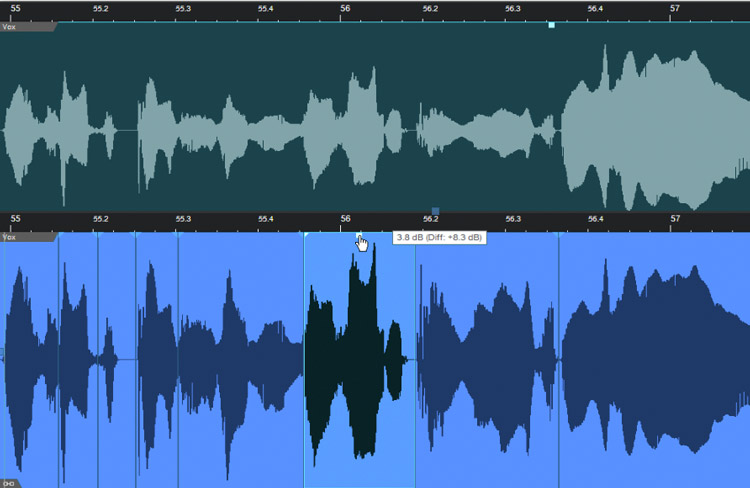
This takes more effort than simply slapping a compressor on a track, but the sound is far more natural. If you eventually do want to add compression or limiting to make the voice "pop," you won't need to add as much, so the sound will be much more natural.
4. Improve Intelligibility with Equalization
The human ear is most sensitive in the frequency range around 3.5 kHz. So if you really want your voice to stand out, either a high-frequency shelf response that starts around 1 kHz, or a broad boost around 3.5 kHz (or both!) will increase intelligibility dramatically (Fig. 5). You can also cut off the lowest frequencies to reduce sounds below the vocal range.
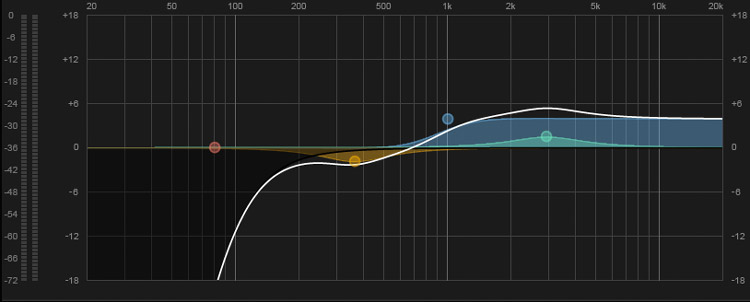
However, there are two cautions. First, a little goes a long way. Because the ear is so sensitive in this range, boosting the EQ too much will create a harsh sound that causes listener fatigue. Use the minimum amount of boost that makes a difference. Second, EQ needs to be different for every voice, mic, and application. The curve above is simply a point of departure—you'll need to experiment to find what's right.
5. Reduce Breath Inhales
With today's editing software, it's possible to eliminate breath inhales entirely. But don't! We're human and we breathe, so cutting out all the inhales sounds just plain... well, wrong. The technique given above for fading in on p-pops can also work with inhales, but often, you want to keep the inhale's sound but lower its level. To do this, split the clip just before and after the inhale (Fig. 6), and reduce its volume level (how you do this depends on the program; usually it's some variation on a volume envelope, or gain change).
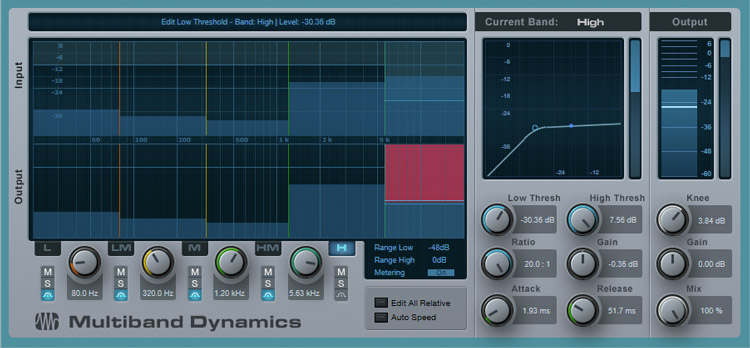
6. The Other De-Esser
Don't have a de-esser plug-in to get rid of nasty sssssbiliants? A multiband compressor can accomplish much of the same effect. Adjust the compressor's highest band to the "ess" frequencies, apply a lot of compression (Fig. 7), and you'll reduce the ess sounds.
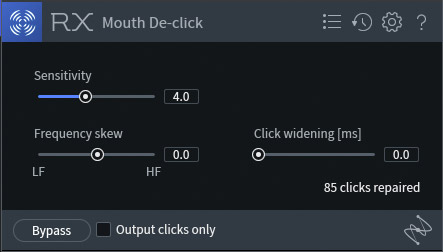
7. And When All Else Fails…
RX7 Standard, by iZotope, is software that's designed specifically for audio restoration and repair. It's not cheap ($399), but its toolset borders on the miraculous for repairing all kinds of voice issues. The mouth de-click (Fig. 8) feature alone has saved me hours (and hours!) of editing, by magically eliminating—not just reducing—mouth clicks. But RX7 also does de-essing, breath control, clipping repair, leakage minimization, ambiance reduction, and a lot more.
Granted, some of these techniques require time to get right... but the difference they can make in the sound quality of voice and narration tracks is huge.
About the author: Craig Anderton is an internationally recognized authority on musical technology. As a musician, producer, and engineer, he has played on or produced over 20 albums and has mastered hundreds of tracks. He has authored over 35 books and more than 1,000 articles for Guitar Player, Sound on Sound, Electronic Musician (which he co-founded), Pro Sound News, Mix, and several international publications. Visit his website here.